3. 운영체제 (2)
CPU 스케줄링
운영체제는 다양한 프로세스와 스레드에 CPU의 사용을 배분함으로써 CPU의 자원을 관리
→ CPU 스케줄링
프로세스와 스레드 모두 CPU의 스케줄링의 대상.
실행의 문맥을 가지고 있으면 모두 스케줄링이 가능하기 때문
우선순위
운영체제는 프로세스별 우선순위를 판단하여 PCB(Process Control Block)에 명시
우선순위가 높은 프로세스에 CPU를 더 빨리, 더 많이 할당
기준
- CPU 활용률: 전체 CPU의 가동 시간 중 작업을 처리하는 시간의 비율
- 운영체제는 높은 CPU 활용률 유지를 위해 입출력이 많은 프로세스의 우선순위를 높게 유지
프로세스들은 CPU와 입출력장치를 모두 사용해 실행과 대기를 반복
- CPU 버스트: CPU를 사용하는 작업
- I/O 버스트: 입출력 장치를 기다리는 작업
해당 프로세스가 어떤 작업을 더 많이 하냐에 따라
- I/O bound process
- CPU bound process
이 두가지 프로세스는 각자 머무르는 상태가 다르기 때문에 공평하게 사용하면 합리적이지 못하다.
- I/O bound process를 우선순위를 높혀 빠르게 처리한 후,
- CPU bound process를 집중적으로 처리하는 것이 합리적
I/O bound process는 CPU 버스트가 짧기 때문에 뒤로 밀려나면 억울함
스케줄링 큐
- Ready Queue: CPU를 이용하고 싶은 프로세스의 PCB가 들어가는 큐
- 순서 + 우선순위를 고려하여 프로세스 실행
- 타이머 인터럽트 발생(타임 아웃)시 다시 Ready Queue로 이동
- 입출력 발생 시 Waiting Queue로 이동
- Waiting Queue: 대기 상태에 접어든 프로세스의 PCB가 들어가는 큐
- 입출력 완료 인터럽트가 발생할 때 까지 대기
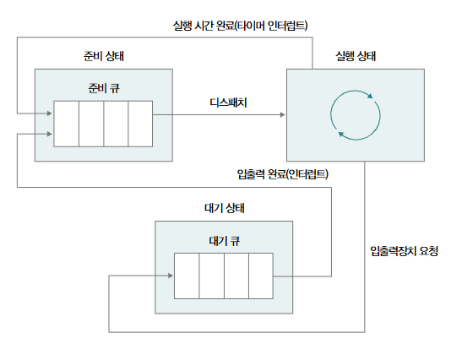
선점형 스케줄링과 비선점형 스케줄링
실행 도중 스케줄링이 이뤄지는 경우
- 실행 상태 → 대기 상태(입출력)
- 실행 상태 → 준비 상태(타이머 인터럽트)
이 두가지 상황에서 모두 수행되는 스케줄링 유형이 선점형 스케줄링
- 운영체제가 프로세스로부터 CPU 자원을 강제로 빼앗아 다른 프로세스에 할당할 수 있는 스케줄링
- CPU의 독점을 막고 합리적으로 자원 배분 가능
- 컨텍스트 스위칭간 오버헤드 발생
실행 상태 → 대기 상태(입출력) 에서만 수행되는 스케줄링 유형이 비선점형 스케줄링
- 어떤 프로세스가 CPU를 사용하고 있을 때 그 프로세스가 종료되거나 스스로 대기 상태에 접어들기 전까지는 다른 프로세스가 끼어들 수 없는 상태
- 컨텍스트 스위칭이 비교적 적어 오버헤드 감소
- 급한 프로세스가 있어도 대기해야함
CPU 스케줄링 알고리즘
1. 선입 선처리 스케줄링(FCFS)
- 단순히 Ready Queue에 삽입된 순서대로 CPU 할당
- 프로세스들이 기다리는 시간이 매우 길어질 수 있음
- convoy effect(호위 효과)
2. 최단 작업 우선 스케줄링(SJF)
- 준비 큐에 삽입된 프로세스 중 CPU를 이용하는 시간의 길이가 가장 짧은 프로세스부터 먼저 실행
- 비선점형 스케줄링 알고리즘
3. 라운드 로빈 스케줄링(RR)
- 선입 선처리 스케줄링 + 타임슬라이스
- 타임 슬라이스: CPU를 사용하도록 정해진 시간
- 삽입된 프로세스들이 순서대로 CPU를 이용하되, 일정시간이 다 되면 다시 큐 맨 뒤로 이동
- 선점형 스케줄링 알고리즘
4. 최소 잔여 시간 우선 스케줄링(SRT)
- 최단 작업 우선 스케줄링 + 라운드 로빈 스케줄링
- 타임 슬라이스만큼 CPU를 사용하되, 남아있는 시간이 가장 적은 프로세스를 우선으로 처리
5. 우선순위 스케줄링(Priority)
- 프로세스에 우선순위를 부여하고, 가장 높은 우선순위 부터 처리
- 우선순위가 높은 프로세스를 먼저 처리하기 때문에 우선순위가 낮은 프로세스는 실행이 안될 수 있음
- 기아(Starvation) 상태
- 기아 상태를 극복하기 위해 에이징(aging)을 통해 대기할 수록 프로세스의 우선순위를 높힌다.
6. 다단계 큐 스케줄링(multilevel queue)
- 우선순위 스케줄링의 발전 형태
- 우선순위 별로 여러개의 Ready Queue를 사용
- 가장 우선순위가 높은 큐를 먼저 처리, 비어있다면 다음 우선순위의 큐 처리
- 우선순위 스케줄링과 똑같이 기아 상태 발생
7. 다단계 피드백 큐 스케줄링(multilevel feedback queue)
- 다단계 큐 스케줄링과 비슷하지만, 프로세스들이 큐 사이를 이동 가능
- 처음 큐에 들어오는 프로세스는 가장 높은 우선순위에 배치
- 타임 슬라이스 동안 실행 후 끝나지 않으면 다음 우선순위 큐에 배치
- 자연스럽게 CPU 버스트가 긴 프로세스는 우선순위 밖으로 밀림
- 프로세스의 큐 이동을 통해 에이징 기법으로써 적용 가능
리눅스 CPU 스케줄링
| 스케줄링 정책 | 적용 상황 |
|---|---|
| SCHED_FIFO | 실시간성 프로세스에 적용되는 정책 (매우 높은 우선순위 할당) |
| SCHED_RR | 실시간성 프로세스에 적용되는 정책 (매우 높은 우선순위 할당) |
| SCHED_NORMAL | 일반적인 프로세스에 적용되는 정책 |
| SCHED_BATCH | 일반적인 프로세스만큼 자주 선점하지 않는 배치 작업에 적용되는 정책 |
| SCHED_IDLE | 우선순위가 매우 낮은 프로세스에 적용되는 정책 |
SCHED_FIFO, SCHED_RR: Real-Time 스케줄러에 의해 이뤄지는 스케줄링
SCHED_NORMAL: CFS 스케줄러에 의해 스케줄링
- CFS: 완전히 공평한 CPU 시간 배분 지향 스케줄러
- 리눅스는 프로세스 마다 가상 실행 시간(vruntime) 존재 → 가중치를 고려한 가상의 실행 시간
- vruntime = CPU를 할당받아 실행된 시간 * $\frac{평균 가중치(상수)}{프로세스의 가중치}$
- CFS는 해당 시간이 가장 작은 프로세스부터 스케줄링
- RB 트리를 이용하여 최소값의 시간을 가진 프로세스를 빠르게 선별 가능
- 리눅스는 프로세스 마다 가상 실행 시간(vruntime) 존재 → 가중치를 고려한 가상의 실행 시간
가상 메모리
물리 주소와 논리 주소
- 물리 주소: 메모리의 하드웨어 상 실제 주소
- 논리 주소: 프로세스마다 부여되는 0번지부터 시작하는 주소 체계
논리주소와 물리주소를 연결하기 위해 메모리 관리 장치(MMU)가 등장
스와핑과 연속 메모리 할당
스와핑
- 대기 상태가 되었거나 오랫동안 사용되지 않은 프로세스를 임시로 스왑 영역(보조기억장치 영역)으로 보냄
- 그렇게 생긴 빈 공간에 다른 프로세스를 적재하여 실행
- 스왑 아웃: 메모리 → 스왑영역
- 스왑 인: 스왑 영역 → 메모리
연속 메모리 할당과 외부 단편화

- 프로세스 A할당 후 프로레스 B를 A의 메모리 주소 바로 다음으로 연속으로 배치
- 외부 단편화 문제 발생
- 프로세스가 실행과 종료를 반복하면 메모리 사이사이에 빈공간이 발생 → 사용하기 어려움
- 메모리 낭비
페이징을 통한 가상 메모리 관리
위 스와핑과 연속 메모리 할당은 2가지 문제 내포
- 외부 단편화
- 물리 메모리보다 큰 프로세스는 실행 불가
이러한 문제를 가상 메모리(virtual-momory)로 해결 가능
- 실제 메모리보다 더 큰 프로세스를 실행할 수 있도록 메모리 관리
- 보조기억장치를 메모리 처럼 사용
- 프로세스의 일부만 메모리에 적재
- 대표적인 가상 메모리 관리 기법
- 페이징
- 세그멘테이션
페이징

프로세스의 논리 주소 공간인 페이지 로 나누고,
물리 주소 공간을 페이지와 동일한 크기의 프레임 이라는 일정한 단위로 나눔
페이지 를 프레임 에 할당하는 가상 메모리 관리 기법
- 물리 메모리에는 불연속적으로 페이지가 배치될 수 있음
- 외부 단편화 발생 X
페이징 기법에서도 스와핑이 적용된다.
대신 프로세스 단위가 아닌 페이지 단위로 적용
- 페이지 인
- 페이지 아웃
즉, 일부는 메모리 적재 일부는 보조기억장치에 적재하여 물리 메모리 보다 큰 프로세스 실행 가능
페이지 테이블
프로세스의 페이지와 실제 적재된 프레임을 짝지어주는 정보
- 페이지 번호 : 적재된 프레임 번호 대응
- 프로세스마다 각자의 페이지 테이블 정보가 있음 → 프로세스를 실행 할 때 페이지 테이블 참조
- PC → 페이지 테이블 → 실행할 프로세스 메모리에 올림
- 테이블 엔트리: 페이지 테이블의 행
- 페이지 번호, 프레임 번호, 유효 비트, 보호 비트, 참조 비트, 수정 비트
- 유효 비트: 페이지에 접근이 가능한지(메모리에 있는지) 여부 → 유효하지 않으면 페이지 폴트
- 보호 비트: 페이지 보호를 위해 존재 r-w-x를 비트로 저장
- 참조 비트: CPU가 해당 페이지에 접근한 적 있는지 여부 → 페이지 교체 알고리즘을 통해 페이지 아웃
- 수정 비트: 해당 페이지에 데이터를 쓴 적 있는지의 여부 → 수정이 되었으면 보조기억장치에도 반영해야함
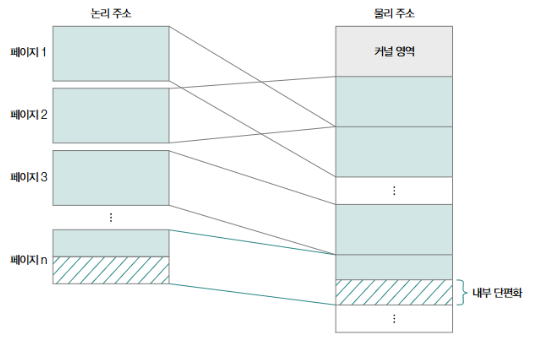
- 내부 단편화의 문제가 있음
- 페이지라는 일정한 크기로 자르지만, 프로세스는 페이지의 크기에 딱맞게 떨어지지 않음
- 페이지 10KB, 프로세스 107KB → 3KB 낭비S
- 어떤 프로세스를 실행하려면 해당 프로세스의 페이지 테이블이 메모리에 적재된 위치를 알아야 함
- 페이지 테이블 베이스 레지스터(PTBR)에 저장되어 있음
페이지 테이블을 메모리에 두는 것은 다음과 같은 문제가 발생한다.
- 메모리 접근 횟수가 많아짐
- 페이지 테이블 접근을 위해 한 번, 실제 프레임에 접근하기 위해 한 번 → 두 배로 메모리 접근
- TLB 라는 페이지 테이블의 캐시 메모리 사용
- 참조 지역성의 원리에 근거해 자주 사용하는 페이지 위주로 페이지 테이블 일부 내용 저장
- 메모리 용량을 많이 차지함
- 페이지 테이블의 크기가 크기 때문에 모든 페이지 테이블 엔트리를 메모리에 두는 것은 낭비
- 계층적 페이징으로 해결
- 페이지 테이블을 페이징 → 다단계 페이지 테이블

페이징 주소 체계
- <페이지 번호, 변위> 와 같은 형태로 저장되어 있음
페이지 교체 알고리즘
요구 페이징: 메모리에 프로세스를 적재할 때 필요한 페이지만을 적재하는 기법
- CPU가 특정 페이지에 접근
- 해당 페이지가 메모리에 있다면 CPU는 페이지가 적재된 프레임으로 접근
- 없다면 페이지 폴트
- 페이지 폴트 처리 루틴을 통해 해당 페이지 메모리에 적재
페이지 교체 알고리즘
- 순수 요구 페이징: 아무것도 메모리에 적재하지 않고 계속 페이지 폴트를 발생 → 결국엔 페이지 폴트 빈도가 줄어들게 됨
- FIFO 페이지 교체 알고리즘: 메모리에 가장 먼저 적재된 페이지 부터 스왑 아웃
- 많이 쓰던 페이지도 스왑 아웃 우려가 있음
- 최적 페이지 교체 알고리즘: 사용 빈도가 낮은 페이지를 교체
- 가장 낮은 페이지 폴트율을 보장
- 앞으로 가장 적게 사용할 페이지를 예측해야 하므로 구현이 어려움
- LRU 페이지 교체 알고리즘: 가장 적게 사용한 페이지를 교체하는 알고리즘
- 가장 보편적인 알고리즘
페이지 폴트의 종류
- 메이저 페이지 폴트: 메모리에 데이터가 없을 경우 보조기억장치에서 메모리로 읽어들이는 페이지 폴트
- 마이너 페이지 폴트: 물리 메모리에는 존재하지만 페이지 테이블에는 없는 경우의 페이지 폴트
세그멘테이션
- 프로세스를 가변적인 크기의 세그먼트 단위로 분할
- 세그먼트의 크기가 일정하지 않기 때문에 외부 단편화 문제 발생 가능
파일 시스템
보조기억장치의 정보를 파일 및 디렉토리의 형태로 저장하고 관리할 수 있도록 하는 운영체제 내부 프로그램
파일
이름, 파일을 실행하기 위한 정보, 파일과 관련한 부가 정보로 구성
- 부가정보: 메타데이터
프로세스는 할당을 받아 사용 중인 파일을 구분하기 위해 파일 디스크립터 라는 정보를 이용
- 저수준에서 파일을 식별하는 정보, 0 이상의 정수 형태
디렉토리
폴더라고도 부름
- 트리 구조로 관리됨
- 루트 디렉토리 (/)를 루트 노드로 하위 노드를
/를 구분자로 사용해 표현
디렉토리 엔트리
- 디렉토리에 속한 요소의 관련 정보를 표로 표현
- 각각의 행을 디렉토리 엔트리라고 함
파일 할당
- 운영체제는 파일과 디렉토리를 블록이라는 단위로 읽고 씀
- 하나의 파일이 보조기억장치에 저장 → 하나 이상의 블록을 할당받아 저장
- 1 블록 = 4090byte

- 각각의 블록이 다음 블록을 가리키는 형태로 할당 가능 = 연결 할당
- 파일을 이루는 모든 블록의 주소를
색인 블록이라는 특별한 블록에서 관리 ⇒ 색인 할당
파일 시스템
파티셔닝
보조기억장치에 여러 파일 시스템을 적용하기 위해 영역을 구확하는 작업
- 하나의 영역을 파티션이라고 함
- 보조기억장치는 여러 파티션으로 나눌 수 있고, 각 파티션마다 다른 파일 시스템 사용 가능
포매팅
- 파일 시스템을 설정하여 어떤 방식으로 파일을 저장하고 관리할 것인지 결정
- 새로운 데이터를 쓸 준비
마운트


- 어떤 저장장치의 파일 시스템에서 다른 저장장치의 파일 시스템으로 접근할 수 있도록 파일 시스템을 편입